Collect Optimization Candidates for Using Intel Hardware Intrinsics in mscorlib #9431
Comments
|
I don't think they are highly used, but System.Buffer.Memmove would likely benefit (adding non-temporal support for large buffers might also be useful). System.Numerics.Vectors may benefit (although outside mscorlib) Other general areas:
|
|
This isn't a specific answer, but I expect we'd see good wins if the methods on string (e.g. IndexOf, Equals, Compare, etc.) and on array (e.g. IndexOf, Sort if possible, etc.) were optimized with these intrinsics Those are used all over the place, including by other core types in corelib, e.g. |
|
Not mscorlib but |
|
@benaadams |
|
There are several implementations of performance critical functions for web based on SIMD both SSE2 - SSE42 and AVX2:
|
|
|
Encoding |
Is that still the case if you use a build from master with RegexOptions.Compiled? In 2.0 that flag did not do anything. If so, do you have a benchmark you could share? @ViktorHofer is considering options for regex perf. |
|
Should have tagged @HFadeel for question above |
|
fyi. @bartonjs @JeremyKuhne |
|
@danmosemsft BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 3 [1709, Fall Creators Update] (10.0.16299.64)
Processor=Intel Core i7-4790K CPU 4.00GHz (Haswell), ProcessorCount=8
Frequency=3906248 Hz, Resolution=256.0001 ns, Timer=TSC
.NET Core SDK=2.2.0-preview1-007813
[Host] : .NET Core 2.1.0-preview1-26013-05 (Framework 4.6.26013.03), 64bit RyuJIT
Job-YJWDPO : .NET Framework 4.7 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.2600.0
Job-IGBXGQ : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job-XFRTQH : .NET Core 2.1.0-preview1-26013-05 (Framework 4.6.26013.03), 64bit RyuJIT
Jit=RyuJit Platform=X64 InvocationCount=1
LaunchCount=1 TargetCount=3 UnrollFactor=1
WarmupCount=1
Java 9.0.1: 4,878875 s |
|
Thanks for measuring that. That's 30% slower than Java. Still plenty of room to improve, including perhaps intrinsics. |
|
At the moment I am trying a few POCs on our codebase. I would really appreciate if I can make this algorithm to work for showcase purposes on a real workload :D // This stops the JIT from accesing originalBuffer directly, as we know
// it is not mutable, this lowers the number of generated instructions
byte* originalPtr = (byte*)originalBuffer;
byte* modifiedPtr = (byte*)modifiedBuffer;
var zero = Avx.SetZero<byte>();
for (long i = 0; i < len; i += 32, originalPtr += 32, modifiedPtr += 32)
{
var o0 = Avx.Load(originalPtr);
var m0 = Avx.Load(modifiedPtr);
if (allZeros)
allZeros &= Avx.TestZ(m0, zero);
if (Avx.TestZ(o0, m0))
continue;
/// ...
/// Lots of stuff that I still don't know if it makes sense to try to go SIMD too.
/// Not interesting for the purposes of making this work :D
} |
|
@redknightlois Thank you so much to report this demand. I will implement SetZero and TestZ after the new year. |
|
I tried |
|
@Tornhoof for (int i = 0; i < XXX; i += 3)
{
res1 += Popcnt.PopCount(data[i]);
res2 += Popcnt.PopCount(data[i + 1]);
res3 += Popcnt.PopCount(data[i + 2]);
}
res = res1 + res2 + res3;Here is my |
|
@fiigii Thank you for your advise, the unrolling increased the performance by another 1-4% (depending on benchmark). This is consistent with a direct benchmark of both variants, where the unrolled one is 5% faster. |
|
@Tornhoof Your code has additional data dependency in the loop. I guess the code below maybe faster. if (Popcnt.IsSupported && Environment.Is64BitProcess)
{
long longResult = 0;
long p1 = 0, p2 = 0, p3 = 0;
for (int i = 0; i + 3 <= BitmapLength; i += 3)
{
p1 += Popcnt.PopCount(xArray[i]);
p2 += Popcnt.PopCount(xArray[i + 1]);
p3 += Popcnt.PopCount(xArray[i + 2]);
}
longResult += p1 + p2 + p3 + Popcnt.PopCount(xArray[BitmapLength - 1]);
return (int) longResult;
} |
|
@fiigii Yes your method is faster, apparently it's even faster to simply add up the counts without any additional variables ark https://gist.github.com/Tornhoof/a35f0bc652aad038556d22dcdd478ef7 |
|
@fiigii Here is a microbenchmark I was implementing as a first step. Corvalius/ravendb@48e0516 Given I couldn't run them I am not entirely sure they would work as expected, they look about right but I may have made a few mistakes here and there. There are both SSE and AVX implementations there. I will be on vacations until the 15th, but I wanted to give you access to the actual code to work on. Hoping you are having a great time in yours. Cy EDIT: I could use Prefetch for another of the POCs I am working on :) |
|
I put up dotnet/corefx#26190 for using |
|
Regarding string.Compare(), see the pcmpxstrx instructions in SSE4.2. Some more info here: How the JVM compares your strings using the craziest x86 instruction you've never heard of |
|
@colgreen I was going to request the following instructions cause I have a use case that I am testing that could use them (both AVX and SSE4.2): So I second your request!! |
|
Just to let you know the goodies are at test already :D Some algorithmic changes and PopCount :) I now need PREFETCH and I can fix the CacheMisses version too :) |
|
@redknightlois Thank you for the data. |
|
Just for reference, so we can close it when done: https://github.com/dotnet/coreclr/issues/5025 |
|
@fiigii Just to let you know that we have put the
Interestingly enough, it appears we are running as fast as we can.
Unless of course using bigger registers also prime the prefetcher in a different way, therefore I can only concentrate prefetches over the L3 cache instead. EDIT: For the record the code this is the code from #5869 with a reworked algorithm to be more cache efficient. The original had a two modes distribution on the 15Gb/sec and 1Gb/sec :) |


|
@redknightlois Thank you so much for the data. I will implement AVX/SSE4.1 TestZ as soon as possible (probably after next week). |
|
@redknightlois, was this using the |
|
@tannergooding yes a mixture of prefetches to L3 from DRAM and per loop prefetching 256 bytes ahead. |
|
We are still not there yet, but @zpodlovics comment on thread: https://github.com/dotnet/coreclr/issues/916#issuecomment-366562117 is also true for us. I mentioned @fiigii out-of-band that we are looking into that particularly in the mid-term but makes sense to make it explicit here too. |
|
@fiigii With the prefetch instruction we should provide a way to know the stride and that the JIT would convert that value straight into a constant when using it. |
|
@redknightlois, I think it might be generally useful to expose access to CPUID (via hardware intrinsics) so that users can make queries about the system directly and so we don't need to worry about exposing an API for each bit added in the future (C/C++ commonly provide a CPUID intrinsic themselves). |
|
@tannergooding While I agree, there is a performance angle why certain EDIT: In a sense they are late binding constants, but the runtime has no concept for those. |
|
I'm definitely interested in the string operations (IndexOf, Equals, Compare, GetHashCode) and also String.Split (or, better, an overload of split which didn't make new strings). There's no CLR method today, but I also do array search (both equality and range queries) with SIMD instructions with huge performance gains. It'd be nice to have something like "BitVector Array.IndexOfAll(Operator op, T value)" which used SIMD underneath. |
@vScottLouvau |
|
A lot of this was implemented already or there are specific issues opened. Let's close this issue and start tracking this area via specific issues. |
Status of Intel hardware intrinsic work
At this time (12/13/2017), we have enabled all the infrastructures for Intel hardware intrinsic and certain scalar/SIMD intrinsics. The next step is to implement specific Intel hardware intrinsics.
Optimizing mscorlib using Intel hardware intrinsic
The base class library (mscorlib) is used by every .NET Core program, so its performance is critical, and we can use hardware intrinsics to improve performance of mscorlib by leveraging modern Intel Architecture instructions. For instance, we experimented rewriting the nonrandomized hash function of
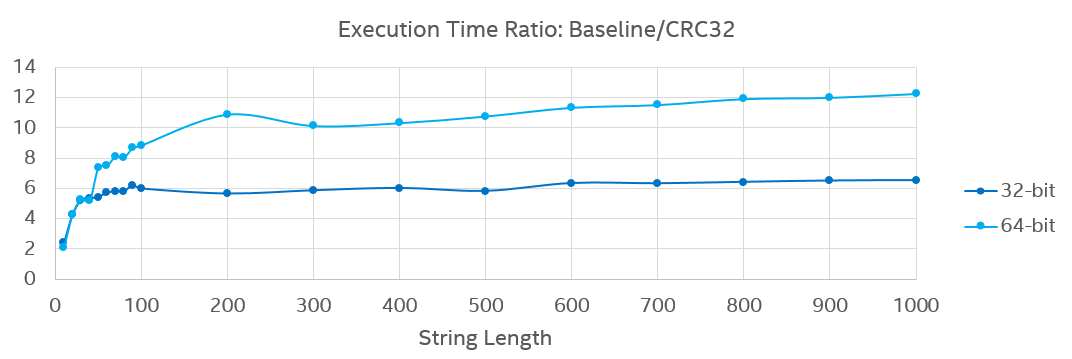
StringwithSse42.Crc32intrinsic in a micro-benchmark. The result showed thatCrc32version provided 2~5.5x(32-bit)/8.5x(64-bit) performance gain on short strings and 6.5x(32-bit)/12.3x(64-bit) gain hashing for longer strings.Capturing optimization candidates
This issue attempts to capture a list of optimization candidates in mscorlib for taking advantage of Intel hardware intrinsics. We are looking for popular use cases from the community and mscorlib authors, and their input on how such methods could be optimized. For example, "we use method XYZ intensively, and if XYZ were to be optimized using intrinsic A and B, we may get X% performance gain". That kind of information could help steer subsequent intrinsic work, with highly demanded hardware intrinsics and many uses cases to have higher implementation priority. In addition, listed below are some general guidelines we plan to use when considering optimization candidates.
Vector256<T>) higher because they have distinctive performance advantage over 128-bit SIMD intrinsics, and AVX/AVX2 machines (Sandy Bridge, Haswell, and above) are widely available and used.Sse42.Crc32available in .NET Core 2.1, other SSE4.2 intrinsics should also be implemented in CoreCLR.The text was updated successfully, but these errors were encountered: