[SUBGRAPH] Validate Balance-centric Subgraph #728
Comments
|
Not sure I like it being called "Solvency-centric", will find better naming of this during the investigation. |
|
Updated to a more granular diagram: Very notable changes:
|

|
Addition to the latest diagram:
|

|
|

|
Failed to distribute reason Total record: 10000 |


|
The Graph Node has an internal concept of gas to measure the resources used up by the event handler (mapper). This "gas" is in no way related to the blockchain gas. In the load test, the event handler is running into one of those limitations. Here is a file specifying some of those limits: https://github.com/graphprotocol/graph-node/blob/master/graph/src/runtime/gas/costs.rs For example, the absolute theoretical max would be to save 250k entities in one event handler. When looking through the code, I don't think there's any way to override these limits, so self-hosting wouldn't help. It's obviously reasonable for Graph Node put a limit somewhere, and from the load testing we can conclude that up to like 5k subscriptions we're good... The question now is whether we go forwards knowing that there clearly is this attack vector. I don't think it matters too much whether the limit is at 2k or 20k or 200k for practical uses. We could still limit the number of subscriber in the protocol to enable this awesome off-chain capability without the attack vector. I also wonder how does the current solvency system handles a situation with a 100k subscriber indexes doing updates. I haven't read the code but I'm gonna take a guess that it's going to do 100k calls to get the realtime balance (not for every event though)? There's probably going to exist some DDOS-ing attack vectors here as well... |
|
I think there is a way to set it but the question is do we really need to support that many subscribers or not?
|


|
|

|
Also note that you can issue 100 distributions to the same index batched in the same block, and that would only require, say, at most 1000 subscribers to trigger the issue. |
|
This is not a good design by abusing current subgraph architecture. We should not bake in undocumented limitations in the system. Note on solvency model: Solvency model is aware of this, but since all subscribers get more liquidity as opposed to less, a "lazy evaluation" of checking their balances is an optimization can be done, and is done in our solvency implementations. So there is no scalability issue in the same way in solvency. |
|
This spike can be considered done, and we will take this findings to the subgraph team. |
The limitation might be per event, not per block. I'll ask in Discord. |
Yep, I get it, probably not an issue here. The solvency sentinel has no rush to account for events that could not affect the balance negatively. Although the sentinel is probably gonna do a RPC call for all the subscribers at some point to account for the new liquidation date?
Limitations can be documented and governed.
The way Subgraph does mapping of events is the most common and straight-forward way for any event-sourced system. Going linearly through the events one by one and projecting at the same time. Its also normal for an event to create many entities -- Subgraph has it documented that theoretically 250k is fine -- but obviously as long as Superfluid is boundless then this can be broken and the mapper would stop. There always has to be a solution / fallback for this scenario anyways when going forwards. The solution?Because putting a cap in the protocol seems to be a definite no go, we can put a subscriber cap in the Subgraph (we're already counting the subscribers). Once an index hits i.e. 2k subscribers, we stop updating the balances of the subscribers for distributions and stop creating the IndexSubscriptionDistributions. The visualizations and activity history will not be perfect for accounts subscribed to these huge indexes... but who cares (i.e. it's a non-issue)... when it works 99%+ of time and nothing critical depends on it. The biggest negative effect of this (or loss of a positive effect) is that when calculating balances, we always have to do a RPC call. If Subgraph had a "perfect history" of balances then we theoretically would not have to rely on RPC calls anymore. RPC calls are what slow down indexing the most. This would still enable us:
|
Got a confirmation that it's per event: graphprotocol/graph-node#2414 (comment) |
Describe the issue:
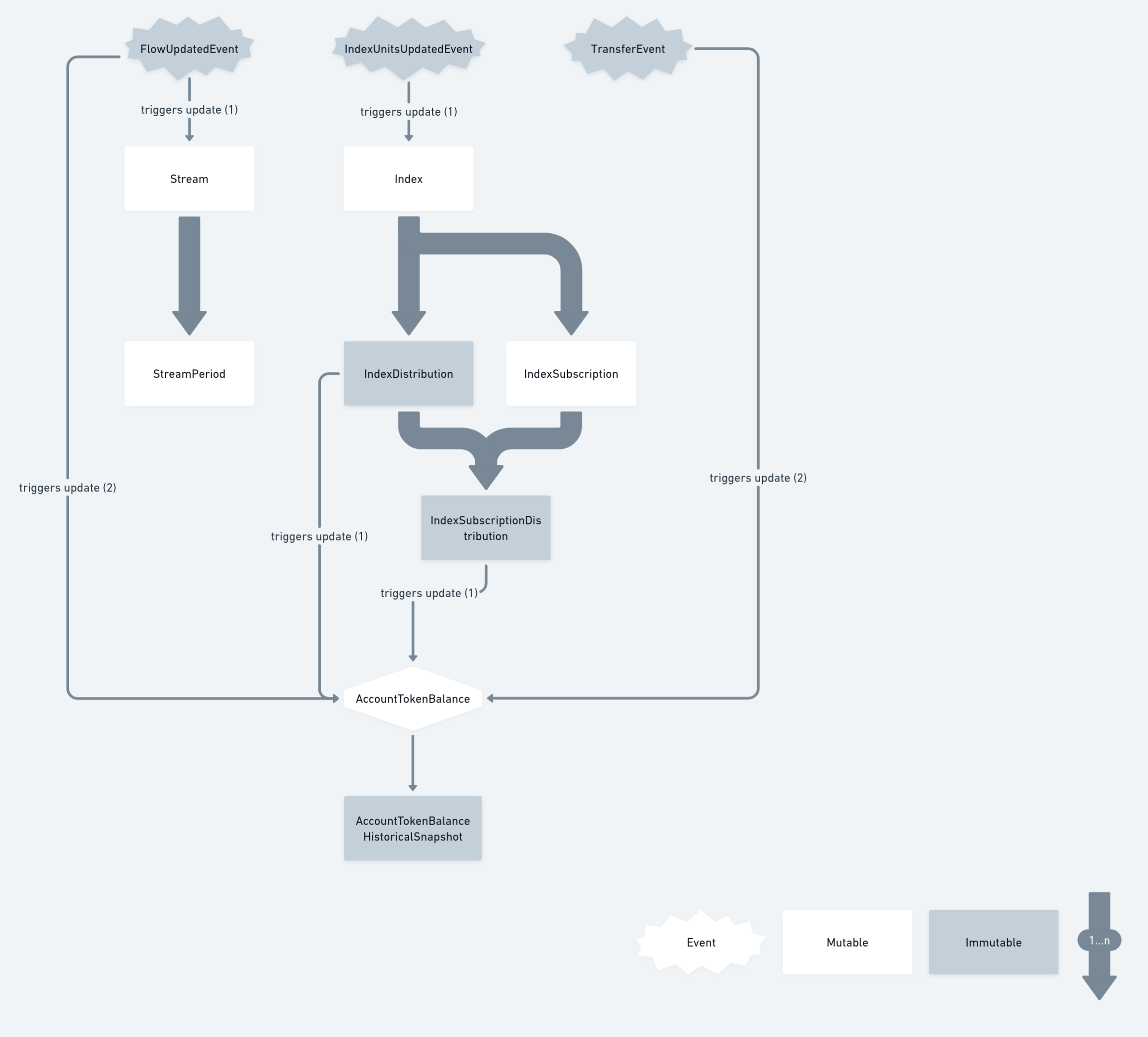
Try building a balance-centric subgraph, per the below design.
The intended benefits are as follows:
Timebox:
This spike should be capped at 3 days and reviewed at the end of the spike.
Additional context:
The text was updated successfully, but these errors were encountered: