TNs with an OrigL quote that ends in a single quote mark fail. #7156
Comments
|
The is related to #7129 |
|
I gave this a 5 estimate, but if the tokenizer has already been updated, this could be a 1. |
|
updating the string punctuation tokenizer to the latest version did not solve the problem. However, after testing the tokenizer on it's own, it does correctly tokenize the quote mark. |
|
Here's where the check validation occurs. https://github.com/unfoldingWord/checking-tool-wrapper/blob/5f0bf79d2f3bb397a0c057db2ebdd7121c7a2ef8/src/components/VerseCheckWrapper.js#L120 |
|
@birchamp I've tracked this bug down to the usfm. See this line https://git.door43.org/Door43-Catalog/en_ult/src/branch/master/56-2TI.usfm#L1040 Notice |
|
Not sure why you think that's a content error @da1nerd ? That's Greek "alla" abbreviated to "all'". A bit like the English possessive in "Jesus'" "hand" (but in our files we use the correct single closing quote character for apostrophe). Ah, maybe you thought that that apostrophe is sentence level punctuation??? It's part of the word indicating the elided/omitted final alpha. |
|
@RobH123 is it correct to say that u2019 should always be considered a word character instead of punctuation? |
|
Ha, no, sorry. Unicode is far from perfect and this is a good example. It's also used as a single closing quote. So ambiguously used at both levels (just to make it harder for programmers) @da1nerd. (Well, not really ambiguous, but you usually have to parse the entire sentence to distinguish them.) |
|
you just made this issue a whole lot more complicated 😆 Given a full sentence, how can I know how to parse it correctly? Does this situation apply to other languages as well or just to the Greek? |
|
Yeah, parsing natural language is an ugly sport. If would certainly be easier if Unicode recommended a different apostrophe character, but apparently one of the initial Unicode policies was "unifying" (rather than "distinguishing"). There is u+02BC which was a (not ideal) possibility to change to, but inconvenient in other ways. Anyway, for English (and Koine Greek too I guess) the long and short of it is: if there's no error in the text, a single closing quote will normally follow sometime after a single opening quote. If it doesn't, and if it appears to be inside or at the beginning or end of a word (i.e., not immediately after punctuation like comma or period, etc.), then it's probably an apostrophe and hence effectively part of the word. (Hope you've still got plenty of hair to pull out.) :-) |
|
Since the initial punctuation usually isn't included in a quote like that, @RobH123 can we make a rule that aligning sentence-level punctuation at the end of a OrigL quote is unacceptable? |
|
@birchamp Yes, I think that's already the rule of thumb, but I can write that specifically into the spec. Hmmh, but then maybe not. What if we wanted a note on the following snippet (pretend it's Greek): Jesus said, “Come!” -- could hardly leave off those final two characters and force the snippet to be: Jesus said, “Come |
|
What if the rule was that the punctuation should not be included unless the initial punctuation is within the quote. |
|
Ha, I'd guessed that you were going to suggest that (should have suggested it myself). Yes, seems sensible enough to me @birchamp, although you should at least consult Larry S on Zulip. It doesn't making the parsing trivial, but should at least make it mostly sensible (hopefully). :-) I guess the rule might be something like: "Only include paired sentence punctuation in a origL snippet if both sides of the pair are included." (Sadly I can think of examples where it might not be possible, but Larry and others would likely know if they actually occur in practice.) |
|
I was thinking it should read something like, "An origL quote should not end in sentence level punctuation unless both pieces of paired punctuation are included in the quote." |
|
@birchamp how should I proceed with this? Without improving the text parsing, the only other solution I see right now is to update https://github.com/unfoldingWord/tc-ui-toolkit/blob/develop/src/VerseCheck/helpers/checkAreaHelpers.js#L28 so that it flattens the verse objects and compares them as a string instead of piece by piece so that in this case it doesn't matter it the quote mark is split off the word. However, I'm not certain if that would have negative side effects. @mannycolon or @PhotoNomad0 might know. |
|
@da1nerd @RobH123 - Ok Per Larry the Greek and Hebrew do not contain quotation marks therefore if the text is an original quote then we can assume that the " ' " u2019 is a needed apostrophe even at the end of an Original language quote. However, @da1nerd do you know if you're using the same code to handle/normalize GL quotes and Original quotes? |
|
that appears to be the case. |
|
Hmmm...that's going to be a problem because we don't want to have this affect how we handle single quotation marks, but in Koine Greek they are apostrophes |
|
@da1nerd did we ever come to a conclusion on this? |
|
No. Perhaps I misunderstood, but I thought there was going to be some more content discussion on this. Either way, I'll need some direction on how we want to proceed. |
|
Yes, @da1nerd ok per https://unfoldingword.zulipchat.com/#narrow/stream/209457-SOFTWARE--.20UR/topic/Helpdesk/near/247737526 we've come to the conclusion that the apostrophe should be shown in original languages even if it's at the end of a field. |
|
ok I've added a |
|
I have a few more modules to update and PRs to make, but it appears that this is working now. |

|
@da1nerd I was just thinking about this today. There's no reason (other than wait times) why the Content Validation can't check every OrigL quote by running your actual JS library functions (alongside my specific checks) if there's a way for me to determine failure. In other words, the CV package could verify our data by running the actual code that our tools run. I would need help knowing what libraries (and what parameters) our tools use. It probably won't give very helpful error messages about what is wrong (data or software), but on the positive side, should be able to verify that our software can process all of our actual data. What do you think? @birchamp also. |
|
@RobH123 I think that's a great idea. It would create a very valuable feedback loop. |
|
@RobH123 that would be handy. |
|
Can you guide me @da1nerd on where to find the function to call (and if not obvious, how to determine if it succeeds/fails)? Is it on npmjs? |
|
@birchamp I discovered some html line breaks in some of the translation notes.
Here's the offending file https://git.door43.org/unfoldingWord/en_tn/src/tag/v52/en_tn_09-1SA.tsv You can see the result of this bug in the linux app |


|
Never seen this before, but since it crashes your build, I added a specific high-priority check to https://unfoldingword.github.io/uw-content-validation/#/Book%20Package%20Checker%20Demo?id=bookpackagecheck (set BP to 1SA and disableLinkFetching to view it -- takes about 4 mins). But I suspect that it was probably a manual error by a human editor that won't happen again. I can fix the file and republish my tomorrow if you like? |
|
Cool, just let me know when it's done so I can restart the build. In answer to your earlier question @RobH123 . I think you'd probably need to use https://github.com/unfoldingWord/tsv-groupdata-parser and pass in your tsv data to it. If you did so then you could perform a number of assertions on the output to make sure it looks the way you expect it to. |
|
@birchamp I hadn't heard yet if the tN had been updated. The builds were failing due to the content bug described here. #7156 (comment) @RobH123 do you know if tN was updated? |
|
Ok, got distracted sorry, but published en_tn v53 just now @da1nerd. Hopefully it will build ok for you now. |
|
I've restarted the builds. We'll see! |
Great catch @da1nerd |
|
Great job guys! I just merged the PR. Thank you. |
|
Works fine in Eph: Tns with OrigL quote ending with a single quote mark highlighted correctly. Some of the Notes given in the example are missing in the project. |
|
Tested in tC 3.0.2 (2ede16e): No longer see an alert for the reference 2 Timothy 3:9 that has a single quote mark "ἀλλ’" (specifically ’ right single quotation Mark U+2019)
This fix also resolves this issue https://git.door43.org/unfoldingWord/en_tn/issues/1540 - tC Ephesians 6:6 Alert Issue for the sub-category "Connect - Contrast Relationship" in tN #1540 where alerts are no longer seen for Eph 6:6, 5:15, Eph 5:27 and Eph 4:29.
|


|
Looks good in translationCore 3.0.2 (38258ea). |
|
Fix tested in tC 3.0.2 build 18ad847 and works fine. |
|
Seeing problem in tC 3.0.2 with migrating old selections due to the above quote fix. Due to the change made in how we handle the u2019 ’ character, the quote arrays are generated differently. So any tn selections that have multiple checks with the same The old parsing of quotes looks like this (example from https://git.door43.org/India_BCS/kn_kglt_2jn_book):
It mistakenly made the accent a new word. The new parsing looks like this:
Unfortunately this makes our existing migration bug (#7198) even worse. It does seem to be a small migration fix at first look. |


|
This is being fixed as part of #7198 |
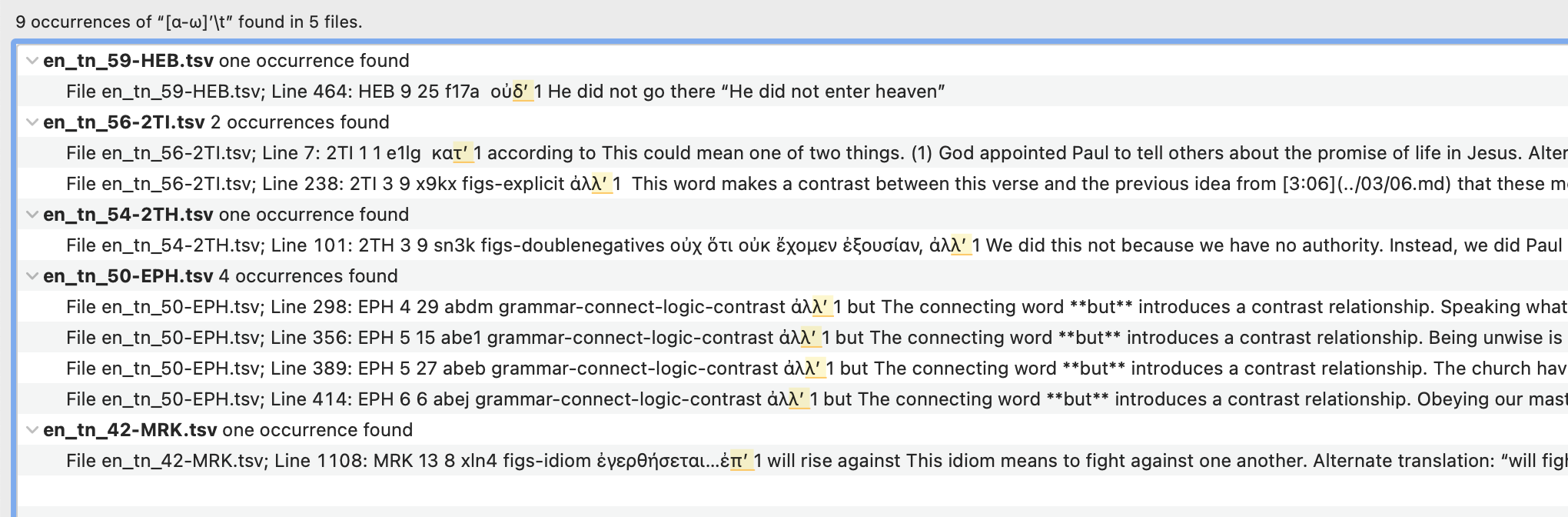
If the OrigL quote ends with a u2019
’, tC reports that there is a problem with the check. (for instance:ἀλλ’in 2 Timothy 3:9 (ID:x9kx) ). tC should be able to handle checks where the quote ends with u2019. For more info see: https://unfoldingword.zulipchat.com/#narrow/stream/209457-SOFTWARE--.20UR/topic/Helpdesk/near/243565499DoD: The checks in the picture below do not fail due to the single quote character at the end of the field.
The text was updated successfully, but these errors were encountered: