AutoMQ vs Kafka: Rate Limiting Best Practices for High Stability Cloud Streaming
Rate limiting is a common practice that systems use to maintain stability when facing sudden traffic spikes. Popular rate limiting algorithms include fixed window rate limiting, sliding window rate limiting, token bucket rate limiting, and leaky bucket rate limiting [1]. The specific principles and implementations of these algorithms are well-documented in other articles and won't be detailed here. This article will focus on how AutoMQ leverages rate limiting mechanisms to handle different scenario requirements.
The most prevalent function of rate limiting is to smooth out traffic spikes. Given that AutoMQ's architecture is based on S3, it also encounters short-term high-volume requests. To prevent these requests from impacting system stability, AutoMQ uses specific rate limiting strategies to smooth out these requests.
The message processing pipeline in AutoMQ is illustrated below:
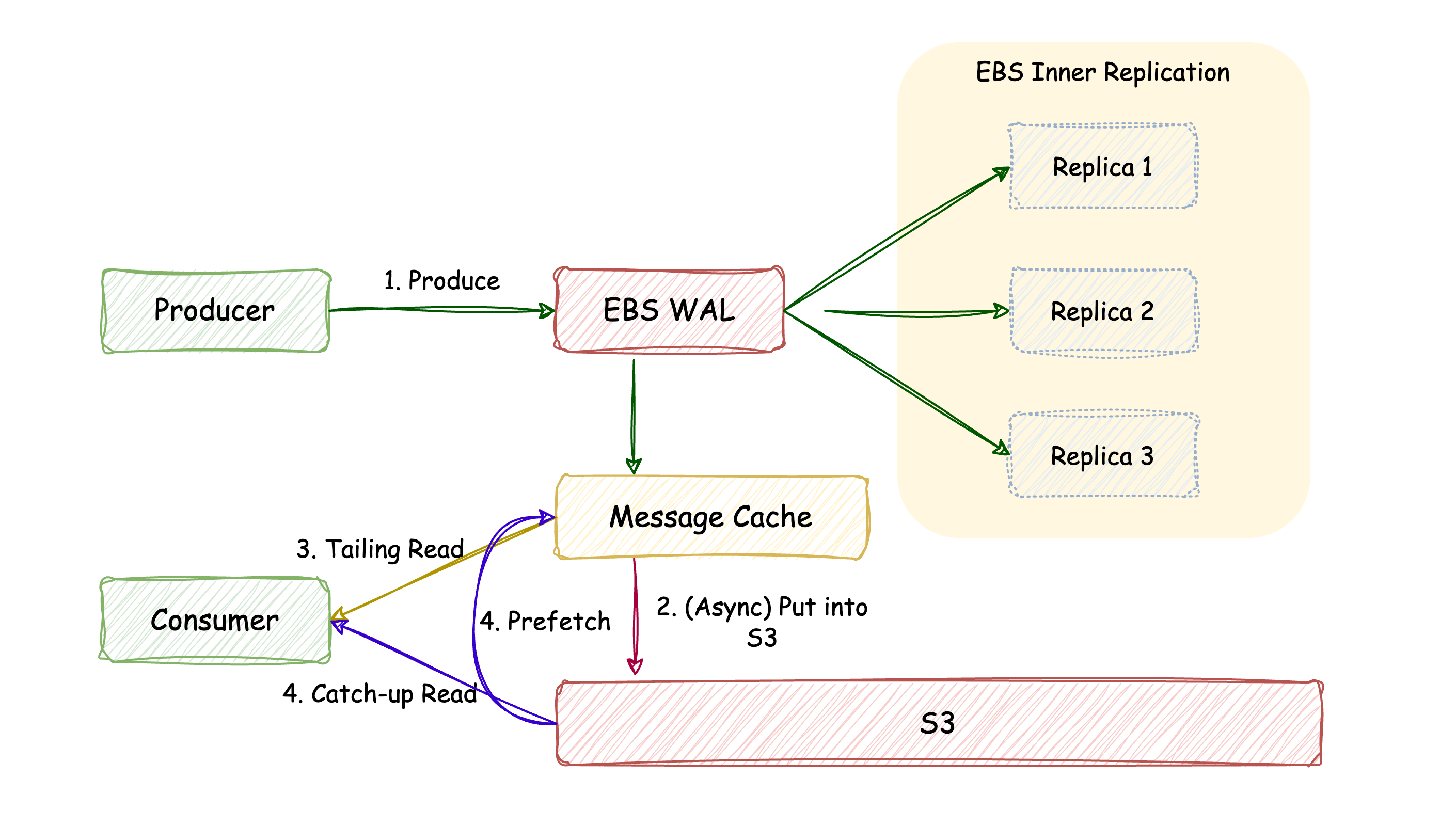
When messages are batched in memory and ready, they are triggered to upload to S3. Given that the default batch size is generally several hundred MB, each upload results in writing several hundred MB of data into the network at one time, causing significant network spikes. Under limited machine bandwidth conditions, this could lead to latency spikes in the regular message processing workflow, affecting business stability. Ideally, the upload rate should match the send rate to achieve smooth upload traffic.
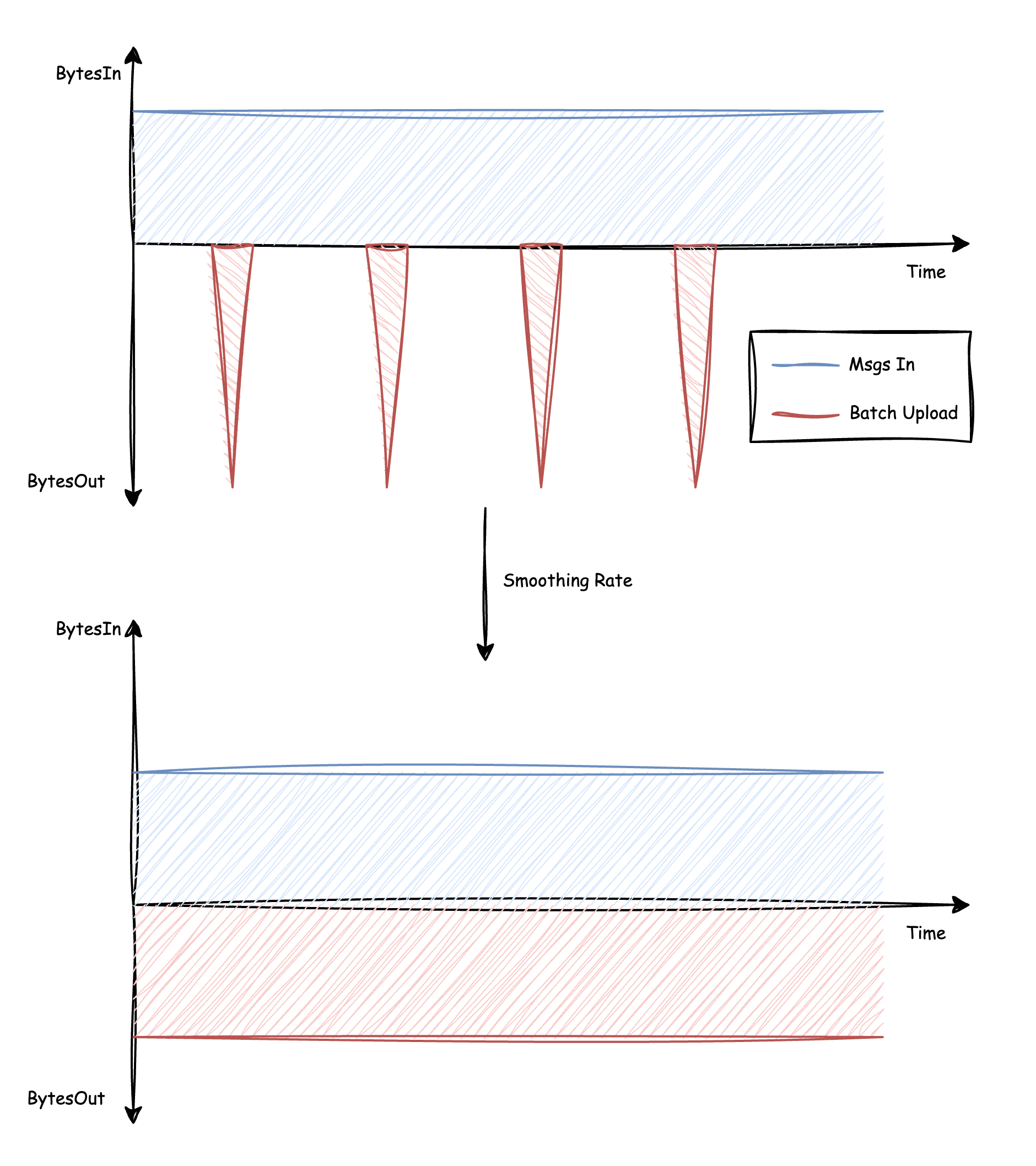
Apart from the regular batching and uploading to S3, during events such as partition reassignment or node failover, AutoMQ will force-upload cached partition data to S3 to ensure new nodes can read the complete data. In these scenarios, the priority of maintaining upload timeliness outweighs smooth traffic. As AutoMQ employs a single-threaded model for data uploading, it requires dynamic adjustment of uploading tasks in such scenarios to complete them as quickly as possible and avoid blocking the partition reassignment or node failover process. To meet these requirements, AutoMQ has implemented an asynchronous rate limiter with dynamically adjustable rate limits based on Guava's RateLimiter: for regular message processing, it calculates a smooth upload rate that matches the send rate; during special scenarios requiring accelerated uploads, the rate limit can be increased to ensure timely uploads.
In a previous article [2], we introduced AutoMQ's Compaction mechanism, which periodically consolidates scattered objects on S3 into large contiguous blocks, effectively improving message retrieval efficiency and reducing metadata size. To avoid excessive memory consumption in the JVM during large-scale compaction operations, AutoMQ splits compaction into multiple iterations. Without applying rate limiting to compaction, the typical system traffic characteristics are as shown below:
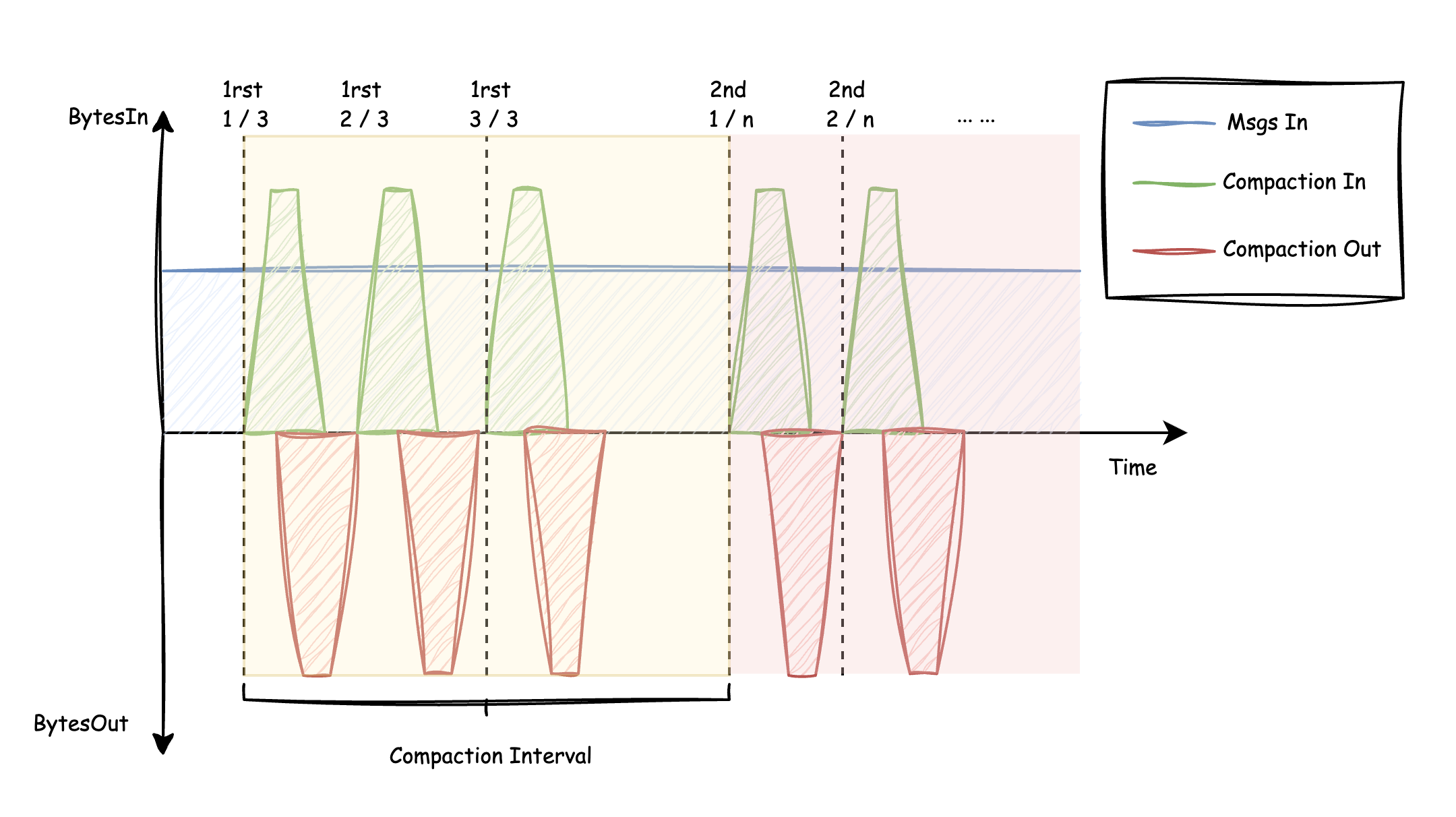
At the beginning of each iteration of every Compaction round, a centralized trigger initiates a read operation to load the data that needs to be compacted to the local storage. After the data is merged locally, it is uploaded as a new S3 Object. By applying smooth rate limiting to Compaction, the read and upload traffic of Compaction is distributed over the entire Compaction cycle. This results in stable "background traffic" within the system, thereby minimizing any spiky impact on the system:

In AutoMQ, there are the following types of network traffic:
-
Message Sending Traffic: Producer -> AutoMQ -> S3
-
Tail Read Consumption Traffic: AutoMQ -> Consumer
-
Chasing consumption traffic: S3 -> AutoMQ -> Consumer
-
Compaction read traffic: S3 -> AutoMQ
-
Compaction upload traffic: AutoMQ -> S3
It is evident that the interaction with S3 leads to an amplification of network read and write traffic. The network bandwidth for an AutoMQ node is calculated as follows:
-
Upstream bandwidth = Message send traffic + Trailing read consumption traffic + Chasing consumption traffic + Compaction upload traffic
-
Downlink bandwidth = Message-sending traffic + Catch-up read consumption traffic + Compaction read traffic
To avoid different types of network traffic competing with each other and affecting production link stability under limited bandwidth, AutoMQ has classified the above traffic types as follows:
-
Tier-0: Message-sending traffic
-
Tier-1: Catch-up read consumption traffic
-
Tier-2: Compaction read/write traffic
-
Tier-3: Chasing Read Consumption Traffic
An asynchronous multi-tier rate limiter, based on the concepts of priority queue and token bucket, has been implemented to manage all network requests. The primary mechanism is illustrated as follows:
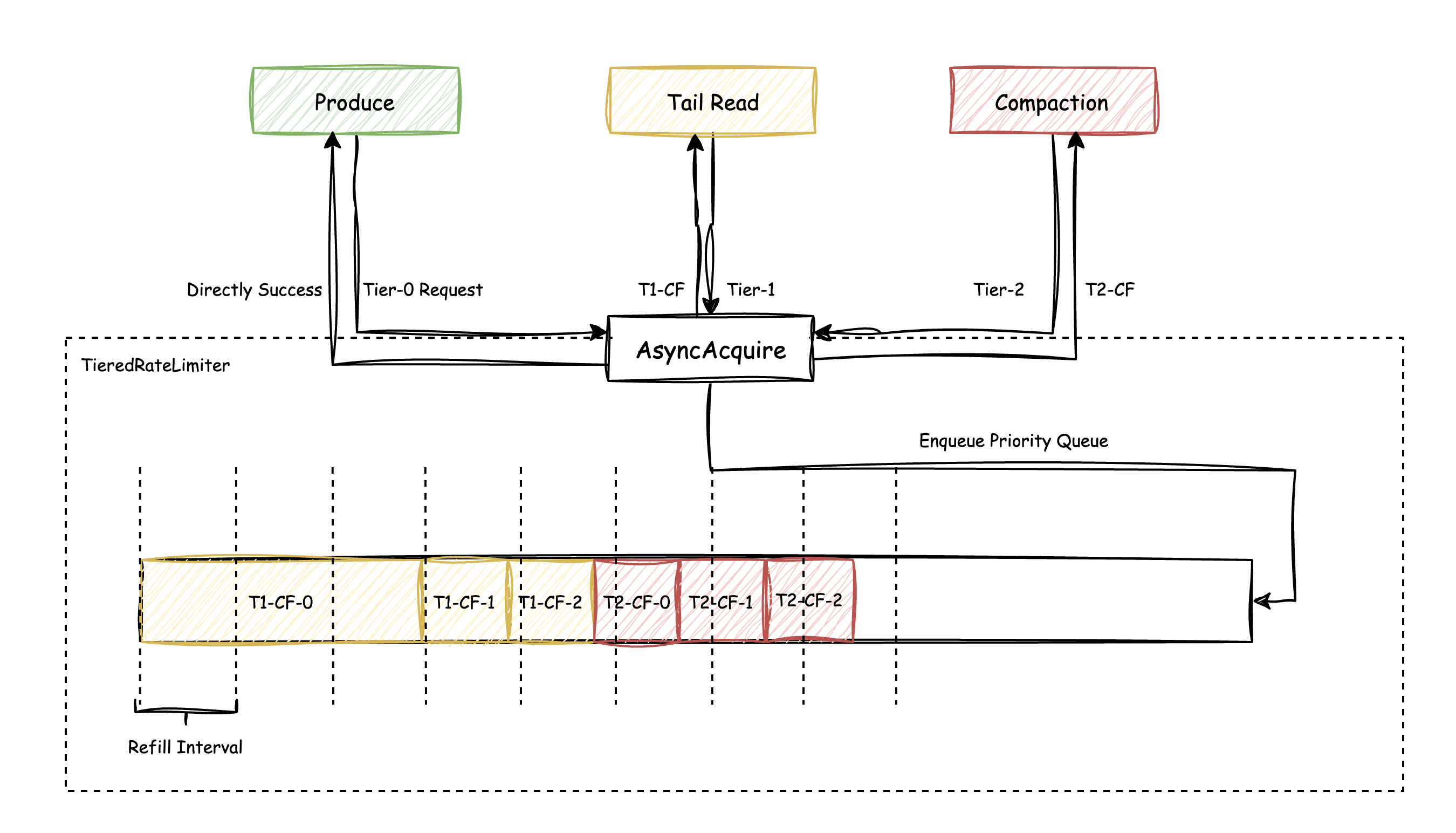
For Tier-0 requests, the rate limiter does not apply any traffic control. Once the corresponding token for a request is deducted, it immediately returns success. For Tier-1 to Tier-3 requests, if the available tokens are insufficient, the requests are placed into a priority queue based on their priority. When tokens are added to the token bucket periodically, the callback thread is awakened to attempt fulfilling the queued requests from the head of the queue. If the token size of a request exceeds the tokens added per refill, the required token size for the request is deducted from the total token size added and reserved for future completion. When enough tokens are accumulated to satisfy the request, it is completed in one go. For example, in the figure, T1-CF-0 is completed after three refill cycles.
The figure below illustrates the multi-tier traffic test conducted with AutoMQ using a refill period of 10ms and a rate limit of 100MB/s. The pressure flow is as follows:
-
Tier-0 traffic fluctuates with a peak of approximately 100MB/s over a 2-minute cycle.
-
Peak traffic for Tier-1 and Tier-2 fluctuates around 60MB/s in 2-minute cycles.
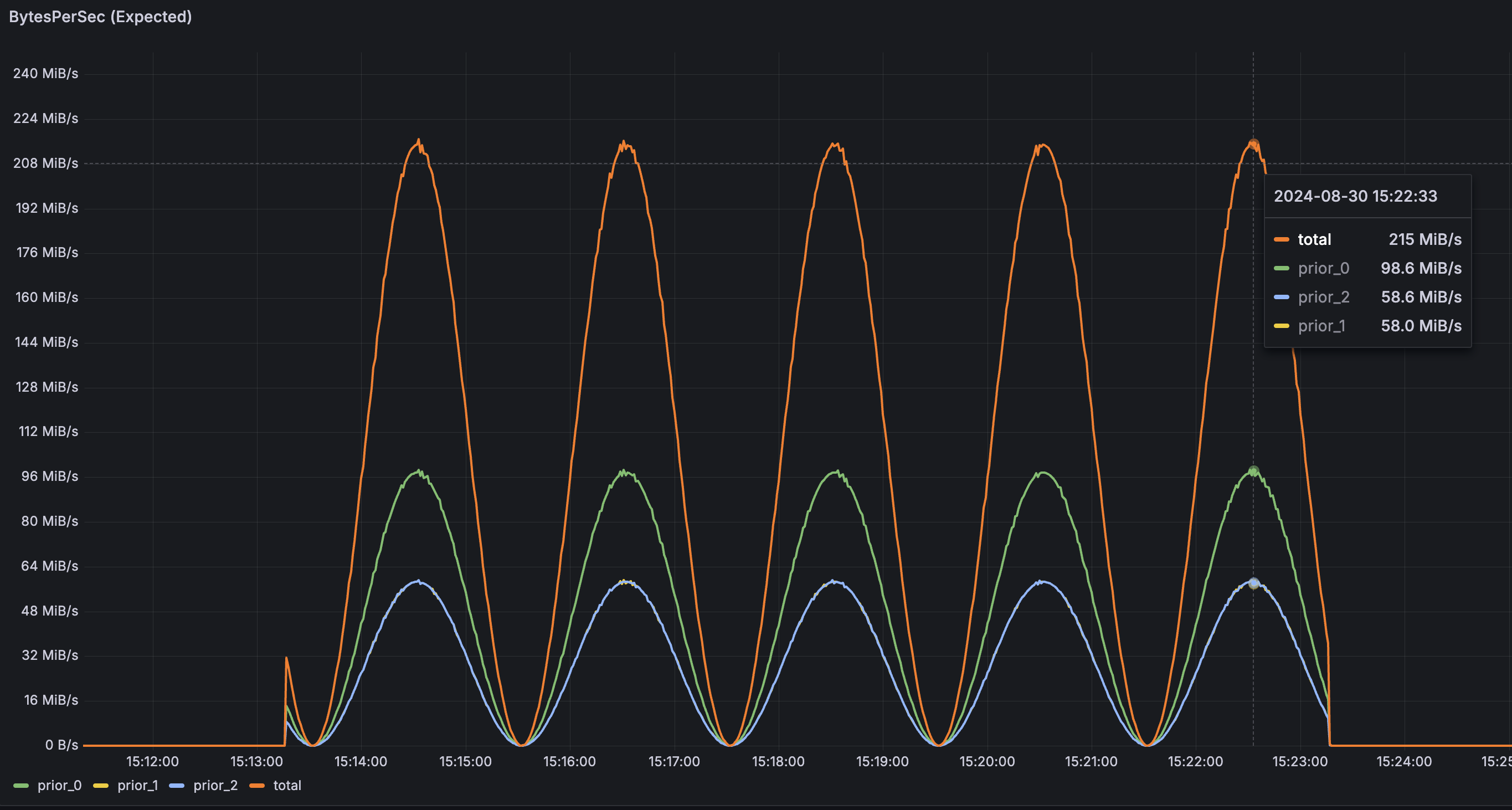
After multi-level rate limiting, the actual traffic curve is as follows:
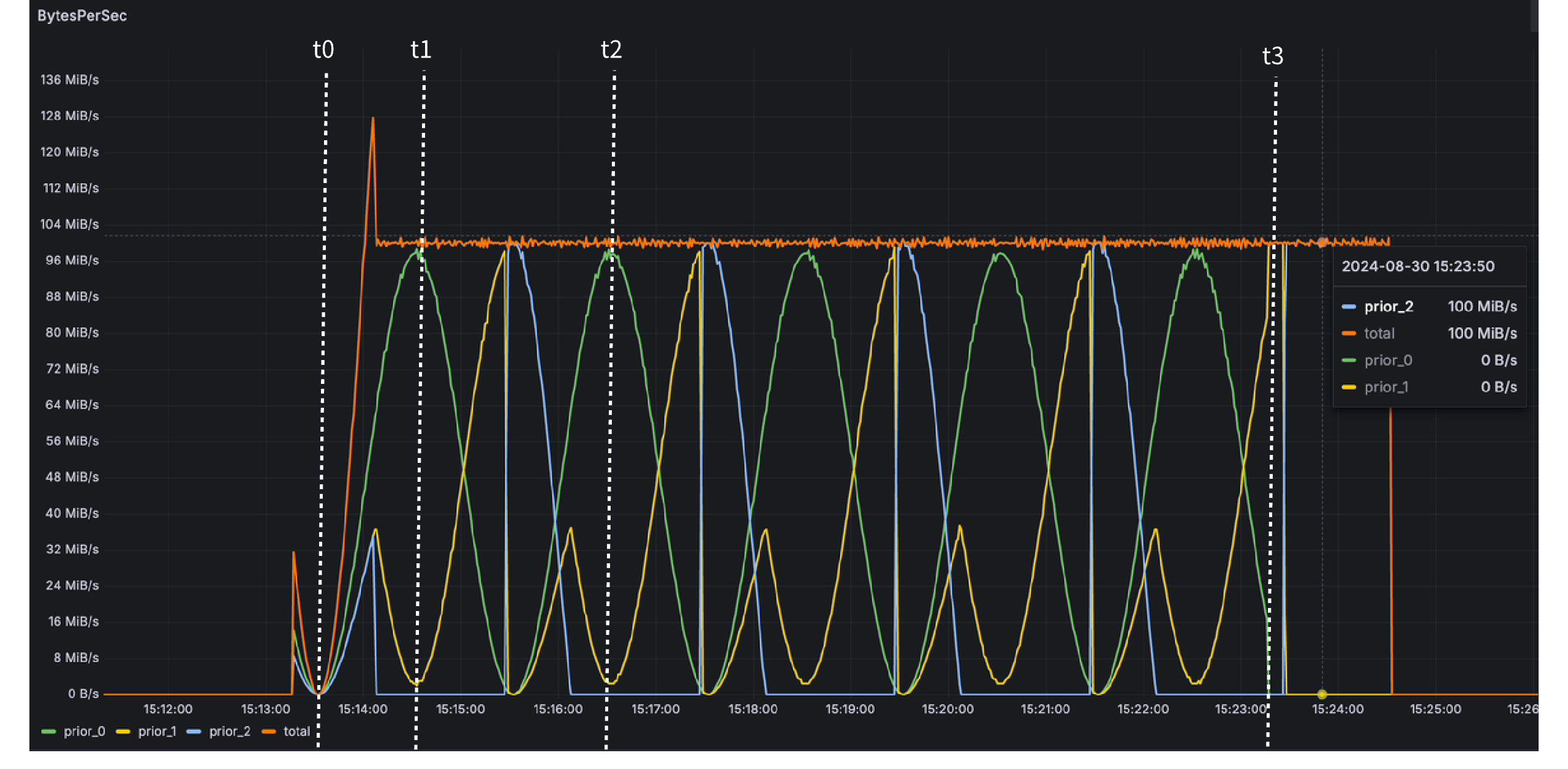
t0 ~ t1: During this period, Tier-0 to Tier-2 traffic simultaneously rises. As rate limit tokens deplete, Tier-2 and Tier-1 traffic drops sequentially based on priority until reaching zero, and pressure requests enter the queue. Tier-0 actual traffic remains unaffected, reaching peak pressure traffic.
t1 ~ t2: During this period, Tier-0 traffic is below peak. The previously queued requests for Tier-1 and Tier-2 traffic are released. Due to higher priority, Tier-1 queued requests are released first, causing Tier-1 traffic to rise before Tier-2 traffic.
t3 ~ end: As Tier-0 traffic ceases, Tier-1 and Tier-2 queued traffic is sequentially released until the pressure traffic depletes, all while maintaining a maximum traffic limit of 100MB/s throughout.
This article explains how AutoMQ utilizes rate limiting mechanisms to smooth traffic and implement tiered control, ensuring system stability in complex production environments.
[1] What are different rate limiting algorithms: https://www.designgurus.io/answers/detail/rate-limiting-algorithms
[2] The secret of efficient data organization in AutoMQ Object Storage: Compaction: https://www.automq.com/blog/automq-efficient-data-organization-in-object-storage-compaction