Understanding Kafka Producer Part 2
Editorial Introduction: This article is the second part of the Kafka Producer principles analysis, detailing the idempotency, implementation specifics, and common issues of the Kafka Producer. [AutoMQ] is a next-generation Kafka fully compatible with Apache Kafka® and can help users reduce Kafka costs by over 90% while providing rapid auto-scaling. As dedicated supporters of the Kafka ecosystem, we are committed to continuously promoting Kafka technology. Follow us for more updates.
In the previous article Understanding Kafka Producer Part 1, we introduced the usage methods and implementation principles of the Kafka Producer. This part will continue to discuss the implementation specifics and common issues of the Kafka Producer.
In a distributed messaging system, various roles may encounter failures. Taking Apache Kafka® as an example, both Brokers and Clients may crash, and network requests and responses between Brokers and Clients may get lost. Depending on the strategies adopted by the Producer to handle such failures, the semantics can be categorized as follows:
-
At Least Once: When a request times out or a server-side error occurs, the Producer retries sending the message until it succeeds. This ensures that every Message is written to a Topic, but duplicates may occur.
-
At Most Once: The Producer does not retry on timeout or errors, sending each Message only once. This approach avoids duplicate messages but may result in Message loss.
-
Exactly Once: The Producer employs appropriate retries to ensure that each Message is written to a Topic exactly once, neither duplicated nor omitted. The Exactly Once semantic is the ideal implementation, capable of meeting the needs of most business scenarios. However, it is also the most challenging to achieve, requiring close cooperation between the Client and the Broker.
Apache Kafka Producer provides two levels of Exactly Once semantics implementation:
-
Idempotence: Ensures that when a Producer sends a Message to a specific Partition, the Message will be persisted exactly once.
-
Transaction: When a Producer sends Messages to multiple Partitions, it ensures that all Messages are either persisted or none at all.
Here, we primarily introduce the usage and implementation of Kafka Producer Idempotence. For the implementation principles of transactional messages, please refer to our previous article: Principle Analysis | Kafka Exactly Once Semantics: Idempotence and Transactional Messages.
Enabling idempotence for the Kafka Producer is quite simple. It only requires setting a few configuration items without the need to modify any other code (the Producer interface remains unchanged).
Related configuration items include:
-
acks
The Producer considers the message successfully written only after the specified number of replicas have received it. The default value is "all".
- acks=0
The Producer does not wait for a response from any broker and considers the message successfully written as soon as it is sent to the network layer.
- acks=1
Producer waits for a response from the leader broker.
- acks=all
Producer waits for responses from all in-sync replicas.
-
enable.idempotence
Enable idempotency to guarantee that each message is written exactly once, in the order in which it is sent. The default value is "true".
To enable this configuration, ensure that `max.in.flight.requests.per.connection` is no more than 5, `retries` is greater than 0, and `acks` is set to "all".
When using this, note that the idempotent Producer can only prevent message duplication caused by internal retry strategies (Producer, Broker, or network errors). It does not handle the following cases:
-
The idempotent Producer only ensures no duplicates at the Session level. If the Producer restarts, it cannot guarantee that messages sent after the restart will not duplicate those sent before the restart.
-
Idempotent Producer ensures no duplication or omission at the partition level, but it cannot guarantee that no duplicate messages are sent to multiple partitions.
-
When the producer times out for various reasons, meaning the sending time exceeds `delivery.timeout.ms`, the producer will throw a `TimeoutException`. At this point, it cannot be guaranteed whether the corresponding message has been persisted by the broker, and the upper layer needs to handle it accordingly.
To achieve idempotence, Kafka introduces the following two concepts:
-
- Producer ID (PID): The unique identifier of the producer. PID is assigned by the broker upon the first message sent request by the idempotent producer and is globally unique. PID is used only internally within the producer and broker and is not exposed to the client users.
-
Sequence Number (hereinafter referred to as SEQ): The sequence number of a message. This sequence number strictly increases along the dimensions of (PID, Partition). In fact, SEQ is stored in the record batch header and serves as the SEQ for the first message in the batch, with the SEQs for subsequent messages in the batch incrementing sequentially.
It is noteworthy that both PID and SEQ are persisted to the log along with the messages.
In fact, besides the aforementioned two attributes, there's also the Producer Epoch, which, in conjunction with the PID, uniquely identifies a Producer. The Producer Epoch has different usages in different scenarios:
For Producers with transactional capabilities (configured with "transactional.id"), the Producer Epoch is also assigned by the Broker. This ensures that only one of the multiple Producers with the same Transactional ID will be effective, known as the "Fence Producer".
For Producers without transactional capabilities, the Producer Epoch is maintained by the Producer itself. It increments when a sequence number reset (Reset SEQ, to be further detailed later) is needed and resets the SEQ to 0.
The following sections describe the steps taken by the server (Broker) and the client (Producer) to achieve idempotency.
The broker stores the state information of each producer in memory, encompassing the producer epoch and metadata of the latest 5 record batches written for each partition (such as SEQ, offset, and timestamp). This is used to determine whether there are any duplicates or missing requests from the producer.
In addition, this state information is periodically snapshotted. When the broker restarts, it restores this state information based on the snapshots and the information in the log.
It is worth mentioning that the hard-coded value of 5 is also the upper limit for the producer configuration max.in.flight.requests.per.connection, which will be explained later in the article.
When the broker receives a record batch, after performing the necessary preliminary operations and before actually persisting it to the log, it checks the PID, producer epoch, and SEQ of the batch. Specifically:
-
Check whether this Record Batch is consistent with the five locally recorded Record Batches. If they are, it is determined that the Producer has sent the Record Batch again for some reason. In this case, no action is taken, and the local metadata (primarily the offset) is directly returned.
-
Check whether the state information corresponding to the PID has been recorded previously. If not, check whether SEQ is 0.
-
If it is, it is considered a new Producer. Record the relevant information of this Producer and write the Record Batch.
-
If not, throw an UnknownProducerIdException.
-
-
Check if the Producer Epoch is consistent with the local record; if not, check if the SEQ is 0.
-
If yes, it means the Producer has reset the SEQ for some reason, update the record, and write to the Record Batch.
-
If not, it will throw an `OutOfOrderSequenceException`.
-
-
Check if the SEQ is continuous with the SEQ of the most recent Record Batch written.
-
If yes, cache the metadata of the Record Batch and write.
-
If not, it will throw an `OutOfOrderSequenceException`.
-
Through the above processing, it can be ensured on the client side that record batches written to the same partition by the same producer are continuous (based on SEQ), without any omissions or duplicates.
The producer's handling of idempotency is relatively more complex, with the following two main challenges:
-
The producer may experience a timeout when sending. During a timeout, there are two possibilities: either the broker did not receive the request, or the broker processed the request but the producer did not receive the response. This makes it difficult for the producer to confirm whether the broker has persisted a produce request that timed out.
-
Producers might send multiple Produce requests to the same Broker simultaneously. When one or more of these requests encounter errors, it is necessary to handle these requests, and subsequent requests differently based on the specific situation.
Before discussing the Producer send process, let's introduce several basic concepts:
-
Inflight Batch
The Producer maintains a record of batches that have been sent but for which a response has not yet been received for each Partition; specifically, for idempotent Producers, it additionally records the SEQ of each in-flight batch and orders them by SEQ.
-
Unresolved Batch
As mentioned earlier, the Producer will retry sending messages several times until the total time exceeds `delivery.timeout.ms`. If a batch experiences a Delivery Timeout, it is considered Unresolved.
When a Batch is marked as Unresolved, the Producer cannot determine whether the Broker has persisted this Batch. Therefore, the Producer can only check whether subsequent Batches of this Batch have been persisted by the Broker (or returned an OutOfOrderSequenceException error). If subsequent Batches are successfully written, then it is assumed that the previous Unresolved Batch has also been completed. Otherwise, it is assumed that the prior Unresolved Batch has not been completed, and the SEQ needs to be reset.
-
Bump Epoch and Reset Sequence Number
When the Producer encounters an issue that cannot be resolved through retries (e.g., all Inflight Batches have responded, but there are still Unresolved Batches; the Broker returns an UnknownProducerIdException error), it will perform Bump Epoch & Reset SEQ operations.
Specifically, it will increment the Producer Epoch, reassign all inflight batches of the errored Partition starting from zero, resend them, and clear the Unresolved Batch.
The process for an idempotent Producer to send a Batch is as follows:
During the sending of a Batch, the Producer will also handle other events (such as processing timed-out Batches), which will be indicated in parentheses.
-
(Judging the status of Unresolved Batches)
-
If it is confirmed that an Unresolved Batch has actually been written, remove it from Unresolved Batches.
-
If it is confirmed that an Unresolved Batch has not actually been written (judging condition: Inflight Batches is empty), then Bump Epoch & Reset SEQ.
-
-
Check if the current Partition can send a new Batch. Scenarios where it cannot send:
-
An Unresolved Batch exists.
-
Previously, a Bump Epoch occurred, and there is still an Inflight Batch with an old Epoch.
-
Previously, a Batch was retrying (meaning that when the idempotent Producer is retrying, the Inflight is always 1).
-
-
(If a Bump Epoch occurred previously and there are no more Inflight Batches with the old Epoch, then reset SEQ).
-
Retrieve the next SEQ for the corresponding Partition and set it in the Batch.
-
Add the Batch to the Inflight Batches.
-
(Check if there are any batches with Delivery Timeout, if so, add them to the Unresolved Batches)
-
Send Produce request to Broker and wait for a response
-
Upon receiving the response, check the Error Code
-
If the error is non-retriable (e.g., AuthorizationException), then Bump Epoch & Reset SEQ, and report the error to the upper layer.
-
If the error is retriable (e.g., TimeoutException), then add it to the retry queue and wait for the next send attempt.
-
UnknownProducerIdException and there hasn't been a prior SEQ reset, then bump epoch & reset SEQ and retry; otherwise, retry directly.
-
OutOfOrderSequenceException and "Unresolved Batch is empty" or "the Batch is exactly the next one after the largest SEQ Unresolved Batch," then bump epoch & reset SEQ and retry; otherwise, retry directly.
-
-
-
Remove from inflight batches and return success to the upstream.
As mentioned earlier, the Producer's configuration `max.in.flight.requests.per.connection` has an upper limit of 5, which is also the number of latest Batches cached by the Broker for each PID in each Partition. This approach is taken because when the number of Inflight Requests (e.g., 2) exceeds the number of Batches cached by the Broker (e.g., 1), the following counterexample exists:
-
The Producer sends two Produce Requests to the Broker successively, both containing a Batch sent to Partition p1, denoted as b1 and b2, where b1 SEQ < b2 SEQ.
-
The Broker sequentially persists b1 and b2 (at this point, the Broker's cache records the metadata of b2), but due to network issues, the Producer does not receive a response.
-
After detecting a timeout, the Producer retries and resends the Produce Request containing b1.
-
Upon receiving the Request, the Broker finds that the SEQ of b1 is smaller than the SEQ of b2 in the cache. It can be inferred that this message is a duplicate and should not be written again; instead, it should directly return offset and other information. However, since the cache does not contain the relevant metadata of b1, the Broker cannot return offset information.
This is the reason why the number of Inflight Requests should not exceed 5.
-
Producer Epoch Overflow Handling
When the Producer Epoch overflows (type is short, with a maximum value of 32767), the Producer will reset the PID and Epoch, and request the Broker to allocate a new PID and Epoch, and Reset SEQ.
-
SEQ Overflow Handling
When the SEQ value overflows (type int, maximum value 2147483647), the SEQ of the next message will roll back to 0. Given the limitations on the number of Inflight Batches and the number of messages in a Batch, no issues will arise.
-
Handling of UnknownProducerIdException
UnknownProducerIdException errors frequently occur in the following scenarios: due to Log Retention limitations, the Broker deletes all messages from a specific Producer in the Log. When the Broker restarts, it no longer has state information for that Producer in the cache. If the Producer then attempts to send messages with the previous SEQ, the Broker will report an error because it cannot recognize the PID.
To handle this situation, the Producer only needs to bump the epoch and reset the sequence, then resend the message.
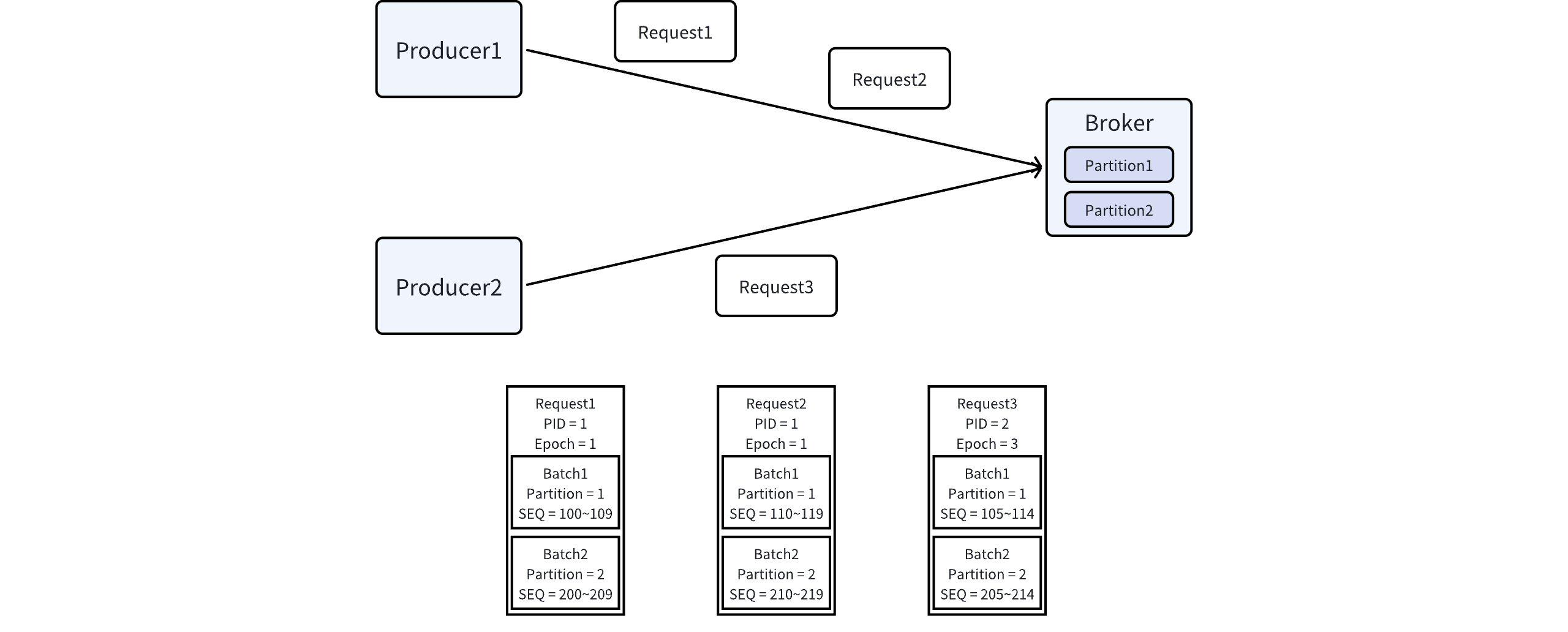
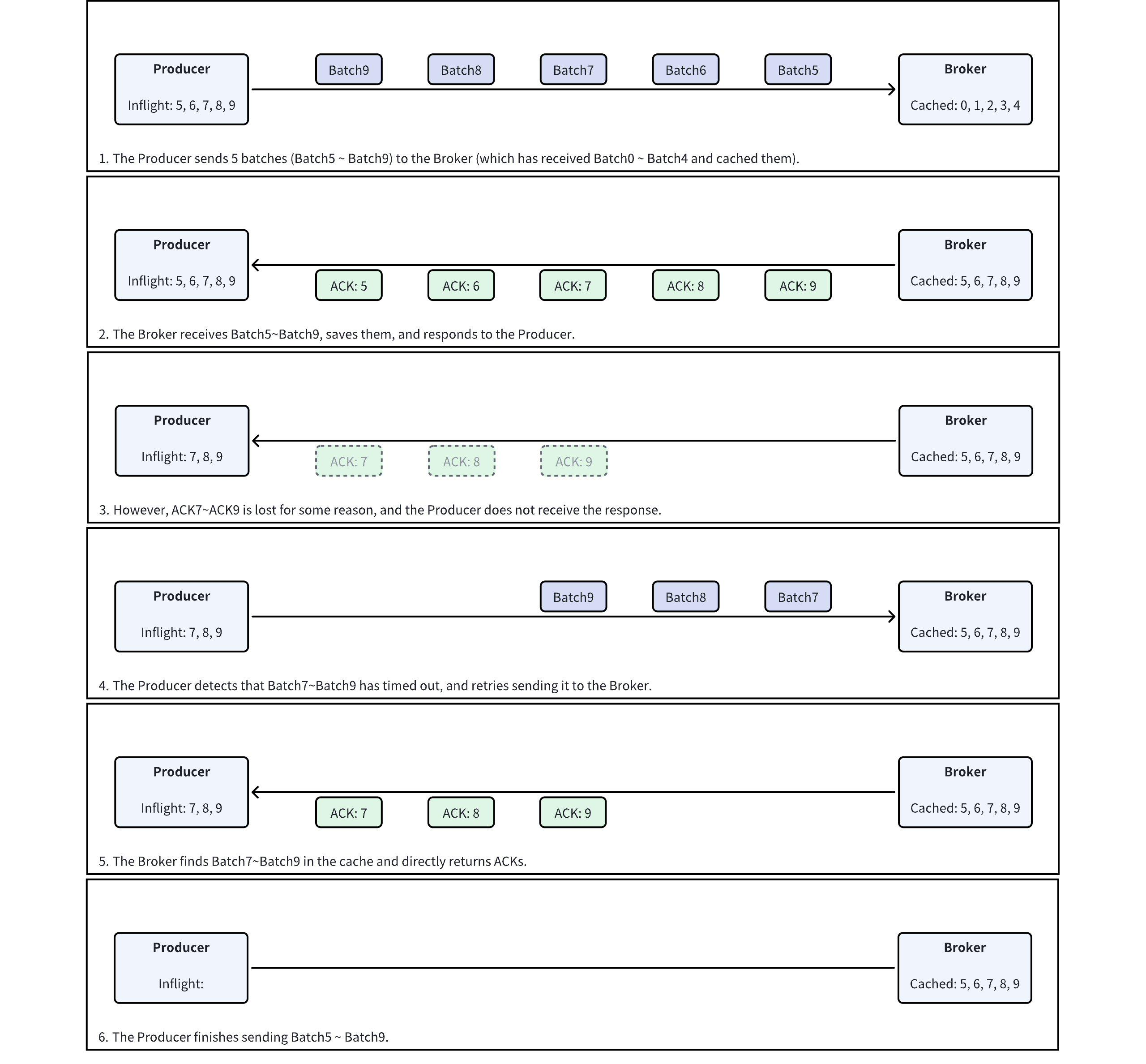
Below are two examples to help understand the implementation of Kafka Producer idempotence.

Below are some implementation details of the Kafka Producer that were not covered earlier.
Kafka Producer supports message compression on the client side to reduce the cost of network transmission and storage of messages. The compression algorithm can be specified using the `compression.type` configuration in the Producer settings. Supported options are `none`, `gzip`, `snappy`, `lz4`, and `zstd`, with `none` being the default, meaning no compression is performed.
Enabling compression can save network bandwidth and Broker storage space, but it increases the CPU consumption for both Producer and Broker. Additionally, since compression is performed at the Batch level, better batch aggregation (larger Batches) results in better compression efficiency.
When implementing message compression, there exists a dilemma: only after the message is actually compressed into the Batch can its actual (compressed) size be determined; yet, to avoid exceeding the batch.size limit, the compressed size needs to be determined before writing the message into the Batch.
To address this issue, Kafka introduced an adaptive compression rate estimation algorithm. The logic is as follows:
-
A Map is maintained, which records the "estimated compression rate" of each compression algorithm on each Topic, with an initial value of 1.0.
-
After a particular Batch is filled and compression is completed, its "actual compression rate" (compressed size / original size) is calculated.
-
Adjust the estimated compression ratio based on the actual compression ratio:
-
If the actual compression ratio is less than the estimated compression ratio, adjust the estimated compression ratio closer to the actual compression ratio by a maximum decrease of 0.005.
-
If the actual compression ratio is greater than the estimated compression ratio, adjust the estimated compression ratio closer to the actual compression ratio by a maximum increase of 0.05.
-
-
When attempting to write messages to a new batch, a new estimated compression ratio * 1.05 is used as the estimate.
Additionally, to handle extreme cases (where fluctuations in message compressibility cause the estimated value to significantly deviate from the actual value), Kafka also supports batch splitting logic.
Batch Splitting (Split Batch) is a feature implemented by the Kafka Producer to address the following scenario: when the aforementioned compression ratio estimate is substantially lower than the actual value, it may result in writing too many messages into a single batch, exceeding the limitations of the broker or topic (message.max.bytes or max.message.bytes). In such cases, the broker will reject the write and return a MESSAGE_TOO_LARGE error.
When this issue occurs, the producer needs to split the oversized batch and resend the smaller batches. The specific process is as follows:
-
Producer encounters MESSAGE_TOO_LARGE error
-
Reset the previously mentioned "estimated compression ratio" to max(1.0, actual compression ratio of the oversized batch)
-
Decompress the batch and reassemble the decompressed messages into new batches based on batch.size (this may generate multiple batches due to the reset estimated compression ratio), then add the new batches back to the send queue
-
(If idempotence or transactions are enabled) Assign SEQ to the new multiple batches
-
Release the memory used by the old batch
The Kafka Producer exposes several monitoring metrics. You can specify the metrics level through the Producer configuration `metrics.recording.level`. The supported options are INFO, DEBUG, and TRACE, with INFO being the default. Currently, all monitoring metrics in Kafka Producer are recorded at the INFO level, meaning they will be collected regardless of the configuration.
Below are the metrics exposed by the Producer and their meanings.
-
batch-size-avg, batch-size-max: The size of each batch. If message compression is enabled, this is the size after compression.
-
batch-split-rate, batch-split-total: The frequency and total number of batch splits.
-
bufferpool-wait-time-ns-total: The time spent waiting for memory allocation from the Buffer Pool
-
buffer-exhausted-rate, buffer-exhausted-total: The rate and total number of memory allocation timeouts from the Buffer Pool
-
compression-rate-avg: The average compression rate of the Batch
-
node-{node}.latency: The latency for a specified Node responding to Produce requests (from sending the request to receiving the response), including all successful and failed requests
-
record-error-rate, record-error-total: The rate and total number of message (not Batch) send failures, including failures during synchronous and asynchronous calls
-
record-queue-time-avg, record-queue-time-max: The time a batch waits from creation to being sent.
-
record-retry-rate, record-retry-total: The frequency and total number of message resend attempts, excluding retries due to Split Batch.
-
record-send-rate, record-send-total: The frequency and total number of messages sent.
-
record-size-avg, record-size-max: The average and maximum size of the largest message in each batch (prior to compression). Note that record-size-avg is not the average size of a message.
-
records-per-request-avg: The number of messages per Produce request.
-
request-latency-avg, request-latency-max: The latency for a Broker to respond to Produce requests (from sending the request to receiving the response), including both successful and failed requests.
-
topic.{topic}: Metrics at the Topic level, including:
-
`.records-per-batch`: The number of messages within each batch
-
`.bytes`: Same as `batch-size-avg`, `batch-size-max`
-
`.compression-rate`: Same as `compression-rate-avg`
-
.record-retries: Same as record-retry-rate, record-retry-total
-
.record-errors: Same as record-error-rate, record-error-total
-
-
{operation}-time-ns-total: Total execution time of each interface in the Client, including
-
flush: Duration of KafkaProducer#flush
-
metadata-wait: Time taken to request a refresh of Topic Metadata from the Broker
-
txn-init: Duration of KafkaProducer#initTransactions
-
txn-begin: Duration of KafkaProducer#beginTransaction
-
txn-send-offsets: Duration of KafkaProducer#sendOffsetsToTransaction
-
txn-commit: Time taken by KafkaProducer#commitTransaction
-
txn-abort: Time taken by KafkaProducer#abortTransaction
-
Below are some frequently encountered issues and their causes when using Kafka Producer.
There are many possible reasons for a Producer experiencing a timeout when sending, such as network issues or high Broker load. Below are two scenarios where a timeout is caused by the Producer.
-
Callback takes too long: The Producer supports registering a callback when sending messages, but this callback runs in the Producer’s sender thread. If the user writes a callback method that performs some heavy operations, it can block the sender thread. Consequently, other messages from this Producer cannot be sent in time, leading to a timeout.
-
Callback deadlock: Synchronously calling the send method within a callback can cause a deadlock. For example, checking for errors in the callback method and calling producer.send().get() if errors occur. As mentioned earlier, the callback runs in the sender thread. Doing so causes “blocking the sender thread while waiting for the sender thread to execute,” leading to a deadlock.
Although the Kafka Producer sends messages asynchronously, there are still some operations that are executed synchronously. If these synchronous operations get blocked for some reason, the thread calling KafkaProducer#send method will also be blocked. Common reasons for blocking include:
-
Refresh Metadata Timeout: In certain situations, the Producer needs to request the Broker to refresh Topic metadata before sending messages, which occurs during the synchronous phase of the send operation. If the Broker is unable to provide service or times out, the Producer will be blocked until a timeout occurs.
-
Producer Buffer Full: When the Producer sends messages at a rate faster than the Broker can process or if the Broker enforces throttling, the unsent messages accumulate in memory (Buffer Pool). When the Producer Buffer is exhausted, the send method will be blocked until buffer space becomes available or a timeout occurs.
There are many reasons why Kafka Producer's CPU and memory usage may increase. Below we introduce some potential situations internal to Kafka Producer that could lead to increased CPU or memory usage. For precise troubleshooting, techniques like flame graph analysis should be used to accurately diagnose the issue.
-
High CPU Usage
-
The smaller the batch size that the Producer accumulates, the higher the frequency of sending batches, which results in higher CPU usage.
-
Enabling message compression will lead to increased CPU usage for the Producer.
-
The Producer caches the partition information and its leader node for a period of time. When sending messages, it iterates through all nodes to check for pending batches to send. Therefore, the more dispersed the partition involved with the producer across nodes, the higher the CPU usage will be.
-
-
High Memory Usage
-
If the rate at which the Producer sends messages exceeds the capacity of the Broker, messages will accumulate in the Buffer Pool, leading to increased memory usage.
-
The larger the batch size of the Producer, the more memory is "wasted" due to each Batch allocating an entire block of memory, thus increasing memory usage.
-
When message compression is enabled, additional buffers are required to perform the compression operation, which also leads to increased memory usage.
-
When the Kafka Producer is running with transactions enabled (transactional.id is configured), if a Fatal Error occurs during a transaction operation, such as ProducerFencedException, all subsequent messages from that Producer will fail to send (regardless of whether transactions are used), and the only solution is to restart the Producer.
At this point, we have provided a comprehensive and in-depth analysis of Apache Kafka® producers. If you have found this content helpful, please feel free to visit the official [AutoMQ] website and follow our official social media channels.